1 Introduction¶
Providing a consistent application deployment environment or platform for all instances of an application provides a number of benefits. It reduces the need for customized installation procedures to be developed and maintained per instance. It eliminates developer uncertainty as to how the software will be operated. It may also reduce the overall IT support burden as it typically requires less effort to perform the same operation across multiple independent but identical environments than planning for and executing different management tasks across heterogeneous deployment platforms.
It is also helpful to think of the “deployment platform”, or simply “platform” as a first class IT concept. Where the platform is a delineation of responsibility between IT operations (those responsible for the physical systems and the overall IT environment) and the self service deployment of applications directly by stakeholders. Of particular note is that the availability of a platform(s) API (E.g. kubernetes), allows high levels of automation and “continuous deployment”. In large scale computing environments, there is often a dedicated “platform team” that works on maintaining this abstraction on top of the traditional IT “silos”.
1.1 Goals¶
This document attempts to define a blueprint and the minimum “seed” hardware for a deployment platform with may be easily scaled to 100s of nodes by simply adding various categories of nodes without requiring a large scale change of architecture.
It also intends to define a reasonable minimum “hardware envelope” to allow rapid initial rollout. Only unremarkable amd64 servers, network equipment, and support infrastructure (PDUs, etc.) should be used in order to maintain flexibility in refactoring the platform. It should be expected that the components that make up the deployment platform will evolve over time based on operational experience.
Enable staff to manage and administer deployments at remote sites.
1.2 Non-Goals¶
In its current form, this document does not attempt to address the entirety of LSST’s IT needs. The focus is on streamlining the deployment of software related to the operation and commissioning the observatory. Data Release Processing, Alert Processing, administrative applications (primavera, magicdraw, email, etc.) and Public Outreach are explicitly not in scope.
This document may conflict with LSE-309 and/or related baseline planning.
It assumes that no VMs, beyond those used internal to the core network services, are required to be “on-prem”. If this assumption is incorrect, this plan should be revised to include a cloud management platform such as OpenStack. Produce a manifest of all physical systems to be installed at each site.
2 Sites¶
The following sites shall be considered the canonical list of “on-prem” deployment locations:
Location |
Abbreviation |
|---|---|
Summit / Cerro Pachón |
|
Base / La Serena |
|
Tucson |
|
Development (@BDC) |
|
It is expected that hardware deployed at each site will evolve separately, but following a common design, to meet the needs of the application deployed at that location. The initial “seed” system deployed at each location is envisioned to be identical.
The above listed abbreviations shall be used to refer to these sites in configuration management code, as DNS sub-domains, etc.
3 Core services¶
3.1 Host Configuration Management¶
CM should be used to manage the basic configuration of most, if not all, amd64 servers capable of running a “standard” Unix user-space. A few examples of the basic items that should be managed are:
authentication/user accounts
sudo config
ssh daemon config
clock timezone
NTP/PTP
selinux
Firewall rules
yum repos
dockerd
Due to existing team knowledge with Puppet, it is an uncontroversial choice as the host level CM tool.
3.2 Bare-metal Provisioning¶
An automated and repeatable method of installing an operating system onto physical servers is necessary in order to provide a consistent computing environment. While in theory this may be done via CM tools such as puppet/chef/ansible/salt/etc., the reality is there is too much “state” to be completely managed, even in a minimal OS install. This also necessitates the ability to re-provision a server back into a known state as it is very common for the configuration to “drift” over time and, as already mentioned, it isn’t practical to manage enough state to drastically change the “role” of a node, without first returning it to a known good state. In addition, bare-metal provisioning is a key component in being able to recover from a “disaster”.
Due to its ability to manage all of the services necessary to support bare-metal provisioning, Eg., PXE booting, DNS, DHCP, tftp, and its integration with puppet, we have selected TheForeman as a single tool to provide:
PXE boot/provisioning
DNS/DHCP management
Puppet “external node classifier”
Puppet agent report processor
Low-level Foreman deployment details are covered in ITTN-011: Bootstrapping the Deployment Platform.
3.2.1 Self-serve bare-metal¶
As the LSST on-prem application environment currently involves a lot of “bare-metal”, it is important to provide a means for end-use engineers to [re-]provision a server without requiring physically laying hands on hardware.
3.3 DHCP¶
A universal core network service which is also needed to facilitate PXE boot.
ISC dhcpd is a very common package and seems to
be the only fully open source dhcp server implementation that has good
integration with foreman. This is unfortunate as the API of this
implementation leaves much to be desired and the dhcpd.leases file has to
be parsed in order to determine the state of the service.
While ISC dhcpd is the only best option for the moment, we should consider switching to ISC Kea as soon as there is a viable foreman plugin available for it. We should also consider contributing to the development of such a plugin.
Puppet code in the lsst-it/lsst-itconf repo is the canonical source for DHCP configuration. E.g.: site/ls/role/foreman.yaml
3.3.1 Static IPs¶
In general, DHCP leases/reservations should be used for most addressing. There are only a few exceptions in which statically assigned IP addresses should be used. Namely:
BMCs on on the core nodes. As the core hypervisor host the VMs which provide DHCP, it is a bootstraping issue to use DHCP for these hosts.
The FQDN/management IPs of the core hypervisor hosts.
Management interfaces and gateways on devices doing layer3 forwarding.
The IPs of forward name resolvers, presumably running on VMs.
Secondary IPs on hosts which can’t be assigned via DHCP due to duplicate MAC addresses.
It may make sense to use static IPs for auth service (TBD)
For virtually everything else, we should relying on service discovery via DNS and keep IP addressing flexible. That includes some management devices such as switched PDUs.
3.4 DNS¶
Automated management of forward and reverse DNS greatly streamlines provisioning. The default choice is often ISC bind but an alternative is to use a cloud hosted service such as route53 with onsite caching nameservers.
We have decided to use route53, initially, across all sites due to
historical problems with “private” DNS zones and cross site/remote access. See
“Split-View DNS and VPNs” in ITTN-004: LSST On-Prem Domain Name Service (DNS) for a more detailed discussion.
Note that reliable on-site name resolution will have to be provided at the summit prior to the start of operations. See “Summit Degraded Operations” in ITTN-004: [Proposed] LSST On-Prem Domain Name Service (DNS).
3.5 Identity Management¶
3.5.1 LDAP¶
A means of managing user accounts is mandatory in all but the smallest of IT environments. This is needed both for “host” level account management and for many network connected services. LDAP is probably the most common choice for linux host level authentication. However, radius, Oauth, or other protocol support may be required for certain use cases (TBD).
An LDAP implementation needs to be provided, at the very minimum:
User accounts
User groups
Ssh key management
A means for end-users to change their own account’s passwords and ssh key set
Replication (to provide redundancy)
We have selected freeIPA as the LDAP (and k5) service and user self-service portal. freeIPA has been well “battle tested” in large enterprises under RedHat Identity Management brand.
3.5.2 Oauth2/OpenID Connect (OIDC)¶
It is common for services deployed into the cloud to use some of “single sign on” system for authenticating users. This often takes the form of an Oauth2 dialect or, increasingly, OpenID Connect https://openid.net/connect/
The service selected should be able to integrate cleanly with generic LDAP and have an existing k8s deployment (E.g., a helm chart). While we are not prepared to propose a specific solution, these are popular options:
3.6 Log Aggregation¶
graylog is a comfortable choice for managing system logs as it is more “syslog” focused that many of the other currently populate general log management stacks.
Due to the heavy footprint of graylog and elastic search, it should be deployed on a k8s external to the core nodes.
3.7 Monitoring¶
For core system operations we require a monitoring system that will do basic up/down monitoring of hosts and generate notifications for state changes.
We have selected Icinga to serve this role due its popularity and familarity to past users of Nagios.
3.8 Artifact Repositories/Mirrors¶
At least the summit will require an on-site binary artifcat and docker image repos in order to be able to continue operations without external network connectivity. In addition, we desire the ability to maintain on-site mirrors of OS packages in order to improve the speed and reliability of provisioning and updates.
We well need to be able to host at least these types of repos:
Docker images
OS Yum mirrors
Yum repos for inhouse software
Misc. binary artifacts needed for deployment
The project has formaly selected the open source variant of Nexus Repository Manager for deploying observatory control software. See: LSE-150 Control Software Architecture.
This requires that an instance of Nexus is maintained, at a minimum, at the summit. We believe that the ultimate architecture will be to maintain a more publicly accessible instance for developers to push artifacts too. For example, using the current development instance as the “canonical” repos repo-nexus.lsst.org/nexus/ which are then mirrored to a summit instance. We also envision that nexus will be deployed upon kubernetes.
However, we would like to maintain the possiblity of using a different package for maintaining mirrors of upstream software that is seperate from the nexus instance(s) used for hosting project produced artifacts. Of concern, is that it may not be possible to configure nexus to mirror the entirity of a yum repo, which may result in only frequently accessed packages being cached within a nexus “proxy” repo instance.
We note that that Pulp is a popular option for maintaining complete mirrors of yum repositories and the a kubernetes operator for pulp is under active development.
3.9 Rancher¶
As we are planning to deploy some core services, E.g., graylog, upon
Kubernetes, we need a means of managing k8s authentication and authorization
because “out of the box” k8s does not provide a means of integrating with LDAP or
IPA.
rancher has been selected to provide a k8s management dashboard and to handle authn/authz integration with freeipa. Rancher is essentially the only fully open source management solution that works with “vanilla” k8s clusters. We also appreciate that commercial support for Rancher is available.
We initially intended for there to be only a single instance of rancher running at the summit, which would manage kubernetes clusters across all sites. This was primarily motivated as a means of reducing cost should we decided to purchase a support agreement. However, with the ongoing shutdown of the summit, we have switched to a “rancher per site” model. Where the site rancher handles all k8s clusters local to that site.
4 Kubernetes¶
We determined that these were the desirable properties of a k8s distribution/installer.
Support for bare metal
Fully opensource
Active user community
Commercial support option
There are many kubernetes deployment options, including the official
kubeadm utility. However, it was difficult to find any option that met all
of those goals in 2019. The only identified product to check all of the boxes
was rke.
Our scheme for deployment is to use puppet to prepare k8s nodes with all of
the prerequisites for for a functioning cluster and to install rke. However,
the rke cli is manually invoked from the command line to create, update,
and destroy k8s cluster.
The lsst-it/k8s-cookbook repo
contains README.md files with instructions on how to [re]create our various
k8s clusters.
5 Core Deployment¶
6 Node Types¶
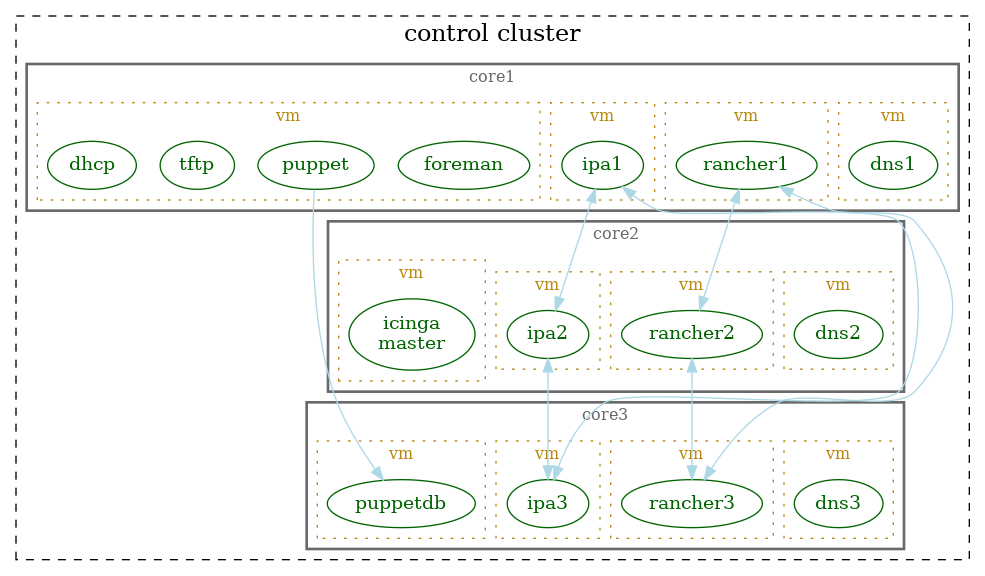
6.1 Common to all node types¶
All amd64 servers shall have an onboard BMC supporting: * IPMI 1.5 or newer * KVM over IP functionality based on html5/etc. IOW – not a java applet and
does not require the client to download and install software.
6.2 Control¶
Provides core services running on a small number of VMs. These nodes are required to “bootstrap” the platform and complexity and the number of services running on them should be minimized.
6.3 k8s master¶
A small k8s cluster, depending on the usage profile, may get away without having dedicated master nodes. In mid to large scale systems, dedicated master nodes are used to keep etcd highly responsive and in some configurations, to ack as dedicated network proxies.
Etcd requires a minimum of 3 nodes for high availability and should be an odd number.
6.4 k8s worker¶
These nodes run most k8s workload pods. In a small cluster without dedicated k8s master nodes, a minimum of 3 is required for H-A etcd.
6.5 k8s storage¶
High-performance distributed file-systems with erasure coding, such as ceph, require lots of CPU, fast storage, and network I/O. Due to highly bursty CPU usage that occurs as Ceph rebalances data placement between nodes, they should be dedicated nodes. Similar to etcd, ceph clusters need at least 3 nodes for H-A operation and an odd number of nodes is preferred.
6.6 Hardware¶
Node type |
Min Quantity |
Sockets |
Memory |
Storage |
Network |
|---|---|---|---|---|---|
Network control |
2 |
1-2 |
128GiB+ |
2x ssd/nvme (boot), 2x nvme ~1TiB |
1x 1Gbps (min) |
k8s master |
0 or 3 |
1-2 |
64GiB+ |
2x ssd/nvme (boot) |
1x 1Gbps or 1x 10Gps (depending on network config) |
k8s worker |
3 |
2 |
8GiB/core min. Eg., 384GiB for a ~44core system |
2x ssd/nvme (boot), 2x nvme ~1TiB+ |
2x 10Gps |
k8s storage |
3 |
2 |
128GiB+ |
2x ssd/nvme (boot), 1+ large nvme (ceph) |
2x 10Gps (min) |
6.7 Platform Seeding¶
The minimal “seed” configuration to boot strap a site would be:
Node type |
Min Quantity |
|---|---|
control |
2 |
k8s worker |
3 |
k8s storage |
3 |
Total per site |
8 |
Total for (summit+base+tucson) |
24 |
7 Networking¶
7.1 Addressing¶
7.1.1 Bare metal¶
A pool of IP address is required for provisioning of bare metal nodes. Managed nodes shall be able to communicate with core services.
7.1.2 k8s¶
The load-balancer service used by kubernetes shall have a dedicated pool of IP address which may be dynamically assigned to services being deployed upon the k8s cluster.
As load-balancer services are created dynamically, and depending on the network topology, may be ARP resolvable to rapidly changing MAC addresses upon different nodes, the underlying network equipment shall not be configured to prevent this. As an example, if 802.1x is in use, it shall not restrict IPs in the load-balancer pool to a single MAC address.
7.2 Access ports¶
7.2.1 BMC¶
A dedicated access port shall be used to connect the BMCs of all systems. This is avoid requiring manual configuration of VLAN tags on BMC sharing a physical interface with the host.
7.2.2 Bare metal nodes¶
Unless otherwise indicated, all hosts will require at least 1x 1Gbps access port in addition to a dedicated BMC port.
Bare metal hosts may require access to multicast domain(s) in use by SAL.
7.2.3 k8s worker nodes¶
Bare metal hosts shall have access to multicast domain(s) in use by SAL.
2x 10Gps ports are required. The access switch shall support LACP groups.
7.2.4 k8s storage nodes¶
At least 2x 10Gps ports are required. The access switch shall support LACP groups.
7.3 KVM over IP¶
The control nodes must be connected to a KVM over IP system in order to allow system recovery even in the event the BMC does not have a working network connection.
7.4 Power management¶
All amd64 servers shall be connected to a remotely switched PDU. Per receptacle metering is preferred.
7.5 PTP/NTP¶
At least one stratum 1 time source local to the site shall be available.
See also: ITTN-009: Summit Time Synchronization
8 Hardware Spares¶
9 Disaster Recovery¶
Only state loss due to equipment failure or malfunction is considered in this section. A strategy to address malicious action is a major undertaking and is greater than the intended scope of this document.
9.1 Multi-site Replication¶
In general, local state (data) that must be retained in the event of a systems failure should be automatically replicated across multiple sites. The method of this will generally need to be per application.
9.2 Configuration¶
Bare-metal deployment configuration should be driven by puppet/hiera and foreman configuration. The puppet plumbing should be in git repositories and possibly published as module on the puppet forge and not require any site specific backup. The foreman configuration database, which will include hostname, IPs, mac addresses, disk partitioning templates, etc. will need to be backed up off site. The backup process is TBD.
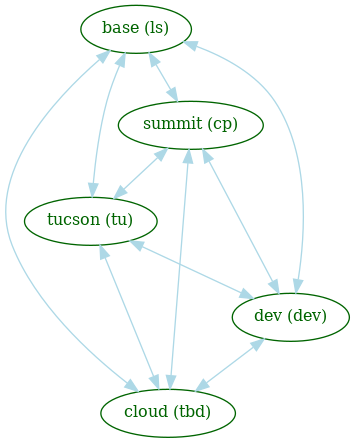
9.3 IPA/LDAP¶
IPA/LDAP services should be federated/replicated across all sites at which “on-prem” software will be deployed. Recovery shall consist of re-provisioning a freeIPA instance and re-establishing replication with other instances.